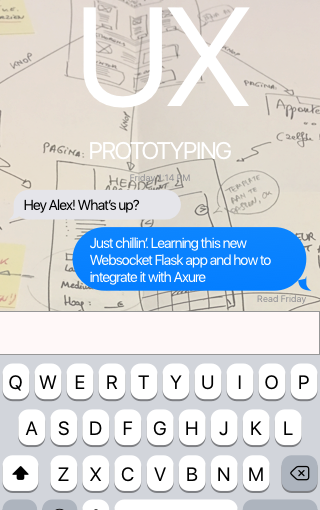
I recently created a prototype sales flow in Axure that contained a dummy chat button. One of the next requests for prototyping that I received was on testing the actual activation of the chat button and the subsequent screens after. However, I went slightly further than only prototyping the chat button interaction.
Why not add live chat to it so you can test end-to-end ?
Since participating on a few U-lab sessions organised by my colleague, I firmly believe that the more realistic your environment, the better the tester can focus on the actual proces that is being tested. It doesn’t need to look exactly right (although that’s fine too) as long as most or all of the functionality is there. Otherwise a tester can become focused on an missing element and not on the actual prototype.
For instance, the sales flow I previously created contains a general conditions text. At first I just added a page to the prototype so the user could at least click on the general conditions link, but I left the actual page empty.
One or two test users found the empty page, and remarked on it repeatedly – it clearly bugged them, even though it was only a very small part of the flow they were asked to test. So I quickly added the beginning of the actual text to the page. Subsequently there were no more remarks.
So instead of using pre made ‘fake’ speech bubbles to ‘make pretend’ that there was a chat session going on, I got to thinking about my previous experiences with Python and Flask and the way you can use those tools to create a website with very little effort.
Wouldn’t there already exist a way to easily setup a live chat server and integrate it with the Axure sales flow prototype ?
A quick google search later I had found a simple tutorial (made by the wonderful knowledgeable Flask-guru Miguel Grinberg) on using websockets with Flask and Flask-SocketIO, setting up a simple chat application server that could be reached by surfing to the page, allowing actual client-server communication using a javascript socket.io library for the webclient.
The backend : live chat application using the Flask micro-framework
Let’s first describe the ‘backend’ : I used Flask together with some extra libraries like Flask-SocketIO to create the chat server.
[Flask is what is called a framework, written in Python, that allows you to code a web application using only a few tools and templating languages that have been configured to work together. It’s called a micro framework because it allows you to work fairly freely, not confining you too much. A full framework is much more rigid in using databases, templating languages, etc]
Soon after, I had a chat server running that allowed you to start up a browser, enter a room and type in a line of text, hit enter, and have it displayed on two different sessions that were in the same ‘chatroom’.
As long as you are on the same (wireless) network, you can visit the server and chat together in a room. So the U-lab organiser or a third party can run the ‘server’ on his mac, and the tester can use a browser on another device to visit the server url (using another id) and we have a live chat going between the two parties.
As I wanted to test the mobile view of it, I modified the provided example to use Bootstrap and css-styled it so that the chat lines are not shown as simple text but as speech bubbles, similar to Messenger. If the user entering the chat line is the same as the user it is being shown to, it is shown on the right side of the screen, else it is shown on the left.
Also, I removed the first ‘login’ screen from the example provided so I could call the chat screen up from within the Axure prototype based on url parameters so the user does not have to login any more.
Obviously this had an impact on using sessions (which is being used by the socket emitters to know who is emitting what), as these sessions were established in the separate login screen.
As I didn’t want to rewrite the whole code and only had a few days to set this up, I made it so that the sessions are actually created by the url parameters when the chat page is called.
The result is something that I consider to be unsafe for real live applications, but is ‘Good Enough’ to use for testing a prototype in a U-Lab.
The frontend : Integrating the Axure prototype with the chat app
The integration with the Axure prototype is fairly easy if you want to link on the desktop : you can code up an action to call an external url when clicking on an element, and decide wether to call this up in a new window or in the current window.
I first tried integrating the chat directly into an inline frame that was inside a dynamic panel, however once you use an inline frame you then lose all the session information and you can no longer chat. So it needs to open in a new window/tab.
However, I wanted to test a mobile prototype, and coupled with the above, this caused some fairly unique problems :
- the user is in the middle of a sales flow, so if (s)he needs to ask for help, (s)he should be able to get back to what (s)he was doing, without restarting the sales flow – so I need to open up the chat application in another mobile window
- we usually install such a web app onto the home screen, so that Mobile Safari opens up full-screen. However, doing that makes it so that a new window created from there cannot be closed – you can only ‘return to the app’ which restarts the app, which is not what we want
- using the javascript command window.close() on IOS to close a chat window and return to the prototype is problematic and not something that works consistently. Some browsers for example restart the whole prototype, or refuse to close the window at all. In the end, I could only use it with the ‘Brave’ browser, a fairly new browser for IOS
In the end, to keep everything on the same server, I published an export of the Axure prototype to html and stored those pages in the local chat server under the static directory (flask can easily serve static files as well).
Conclusion
My prototype can call up the chat in a new window, and the user can be returned to it. It is a worthwhile addition to actually see people start up, use, and end the chat.
Templating the chat page itself is fairly easy, it’s just bootstrap css that you can edit.
The chat server is however more finicky than it should be – if the computer hosting the chat server goes to sleep, it is best to restart the chat server. Plus caching by browsers means that if you do make any changes, you need to make sure that the cache in the (desktop) browser is refreshed. Or you keep wondering why your changes do not become visible…
The actual integration with the prototype was more difficult because I was integrating with a mobile prototype. I’ll have to look into this on how to do a better integration next time.

